网页pdf怎么下载
当我们在网站上看到需要的PDF文档时,往往会考虑网页pdf怎么下载,当我们把PDF文档下载到本地后就可以提高编辑效率和阅览体验。其实想要下载网页端的PDF文档方法很多,同时考虑到网站情况各不同,因此接下来说说这几种方法让用户在尝试下载网页上的PDF文档时有个参考。
使用打印机功能保存PDF
在提到网页pdf怎么下载时,我们可以尝试使用网页的打印功能来保存网页上的PDF文档。我们不需要为电脑配置打印机设备,只要使用打印功能来打印网页上的PDF文档,就会预先完成PDF文档的保存,接下来说说具体的操作流程。
步骤一:在网页上打开PDF文档后等待缓冲完成,点击浏览器的【文件】【打印】选项。
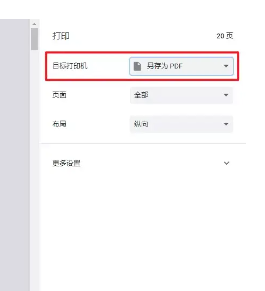
步骤二:在弹出的打印设置窗口时,在【目标打印机】旁边选择【另存为PDF】选项。
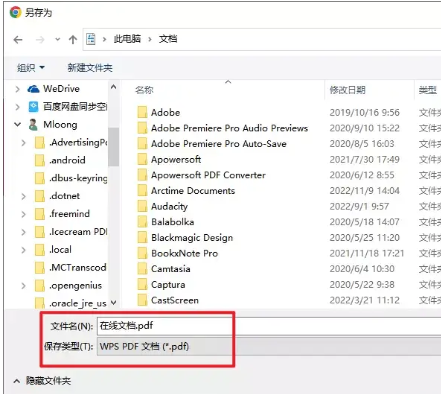
步骤三:这时浏览器就会出现保存窗口,我们设置好PDF文档的文件名和路径,点击【保存】按钮即可。
使用OCR识别功能保存PDF
在提到网页pdf怎么下载时,刚才介绍了直接使用浏览器的打印功能来另存为PDF文档,这种情况适合可以在网页上浏览PDF文档的情况,简单理解就是我们使用浏览器可以看到PDF的全部内容,这就意味着已经把PDF的数据全部下载到浏览器中,而还有一种情况则是网页上只能显示图片格式的PDF文档内容,所以无论是浏览器还是下载软件都无法找到下载链接和渠道,对此就只能使用OCR识别功能,建议下载安装万兴PDF软件再进行如下操作。
步骤一:登录电脑QQ后按下截图组合键【Ctrl+alt+A】将PDF内容截图,然后在截图窗口保存后PDF文档的截图和确认路径。
步骤二:启动万兴PDF后点击首界面的【快速工具】中的【OCR文本识别】选项,然后再点击【打开文件】按钮。
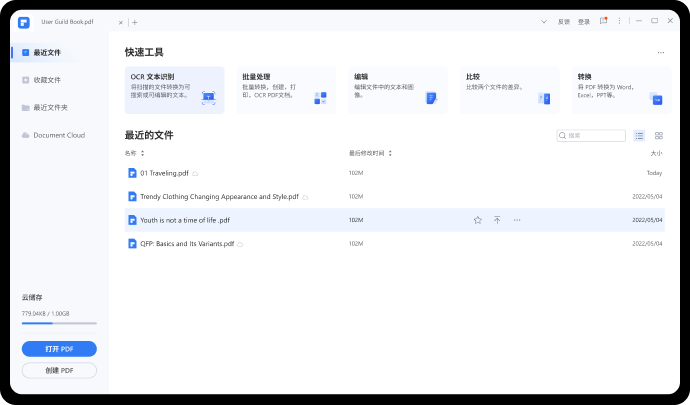
步骤三:在弹出的窗口中打开刚才保存的截图图片,然后点击【执行OCR】按钮即可开始识别转换。
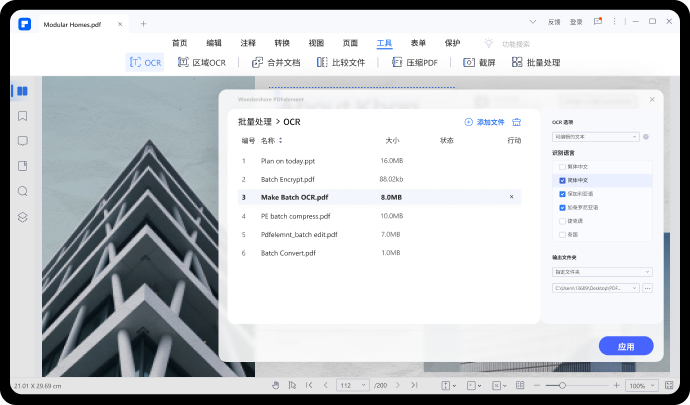
步骤四:万兴PDF完成OCR识别后会把识别出的文本信息保存到新建PDF文档中,点击【打开】按钮即可编辑和预览PDF文档。
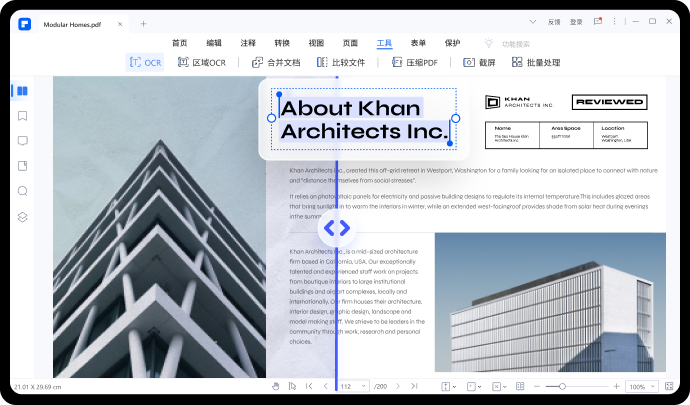
步骤五:如果我们保存的截图中本身就有图片信息,则在OCR识别后新建的PDF文档中点击顶部的【编辑】按钮,再点击【添加图像】按钮。
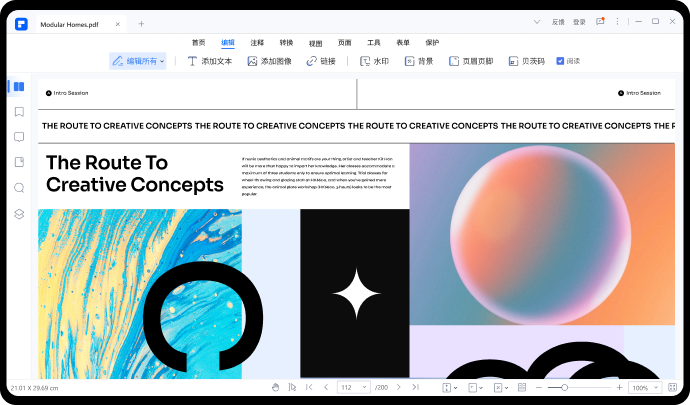
步骤六:在弹出的窗口中选择图片,即可将其插入我们光标所在的位置,还可以通过蓝色边框来调整图片大小和位置。
网页PDF下载注意事项
刚才介绍了两种网页pdf下载方法,通常我们在网页中打开PDF后然后看网址栏显示的后缀为.pdf的话,这种情况往往直接使用下载的方法就可以保存PDF文档,而如果打开网页看到PDF文档内容后,浏览器网址后缀为.html,对此就要使用截图后OCR识别的方式下载PDF文档。
以上介绍的就是如何根据网页上PDF文档情况下载我们需要的PDF文档,使用万兴PDF来进行OCR识别的好处就是只要我们可以看到PDF文档的内容就可以把它转换为可编辑的PDF文档,所以这种方法兼容性更好。
