我们一般会遇到两种PDF文件,一种是有WORD、EXCEL、PPT、TXT等文件格式转化过来的,这种PDF文件我们是可以进行编辑和修改的,另一种是扫描件转换过来的PDF文件,这种PDF文件是不可以进行编辑的,即使转换成WORD得到的也是一张图片,同样不能进行编辑。这时,我们可以借助OCR文字识别软件,提取PDF文件中的文字,然后再进行后续的编辑。
OCR文字识别是我们经常会用到的办公软件,操作方法简单,只需简单的操作,就可以识别并提取出PDF文件中的文字。市面上这类的OCR软件有很多,今天就以我们之前下载过的万兴PDF为例,来为大家介绍一下如何提取PDF文件中的文字。
使用万兴PDF提取PDF文件中文字的步骤:
1、下载、安装并运行万兴PDF,打开需要提取文字的PDF文件;选择首页菜单栏之下的“转换”功能,点击选择“OCR”。
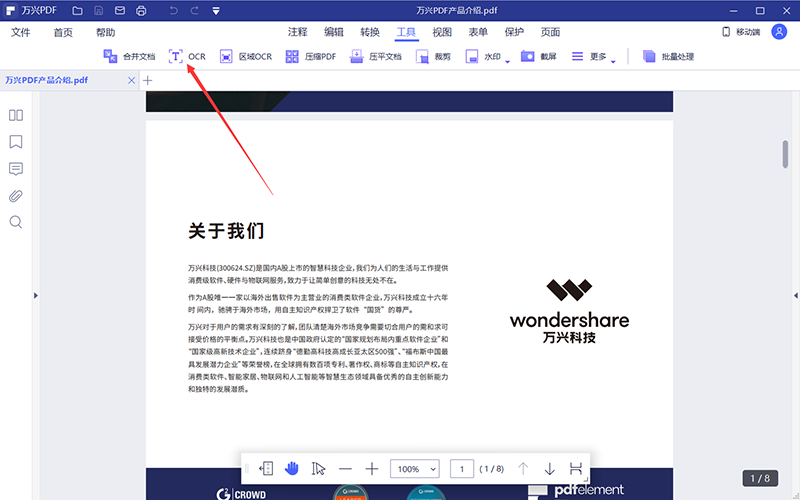
2、如果之前没有通过万兴PDF下载过OCR组件,此时会提示下载OCR组件,直接点击下载即可。
3、OCR插件安装好之后,会直接进入OCR识别的设置界面。
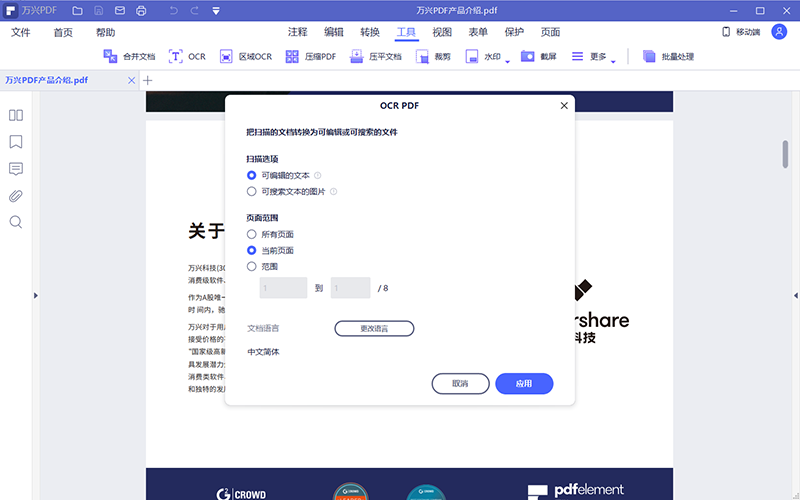
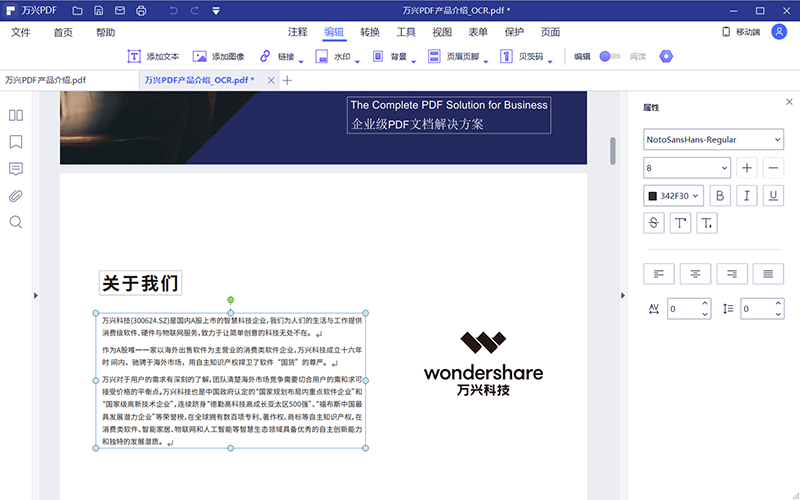
在这里我们可以选择“可编辑的文本”,这样我们就能直接在现有的PDF文件里进行编辑了,当然如果只是想提取文字,选择“可搜索文本的图片”就可以了;
点击“更换选择”可以选择中文、英语、日语、俄语等语言;
“自定义页面”是用来设置此次操作的页面范围的。
4、设置好之后点击确定,就可以进行PDF文件的文字提取和编辑工作了,这时我们可以看到,PDF文件中的文字已经被文本框框住,这是我们就可以对文字进行复制、粘帖、删除、编辑等操作了。
另外,上述的OCR文字识别提取工作,我们还可以HiPDF中进行操作(OCR文字识别提取线上操作地址:https://www.hipdf.cn/ocr),大家可以根据自身情况进行选择。